Stellen Sie sich vor, Sie befinden sich in einer riesigen Fabrikhalle und können dort von jedem beliebigen Objekt, wie z.B. Palettenbehältern, Produktionsteilen, Werkzeugen, usw. jederzeit den aktuellen Standort auf Ihrem Smartphone sehen und dorthin navigieren. Dies ist kein Zukunftsszenario mehr, sondern dank der Indoor-Positionierung bereits Realität. Diese Technologie ermöglicht es, Objekte oder Personen innerhalb von Gebäuden genau zu lokalisieren – ein Bereich, in dem das klassische GPS aufgrund fehlender Satellitensignale oft versagt. Besonders im Kontext von IoT (Internet of Things) wird Indoor-Positionierung immer relevanter. Hier können Ortungstechnologien dazu beitragen, effizientere Abläufe zu gestalten, Nutzererfahrungen zu verbessern und neue Anwendungsfälle zu ermöglichen.
Es gibt verschiedene Ortungstechnologien, die für die Indoor-Positionierung geeignet sind und die je nach erforderlicher Genauigkeit (Granularität), Kosten und Zuverlässigkeit besser oder schlechter für den jeweiligen Einsatzzweck im IoT-Projekt passen können. Im Folgenden stellen wir die 4 wichtigsten Ortungstechnologien für die Indoor-Positionierung vor.
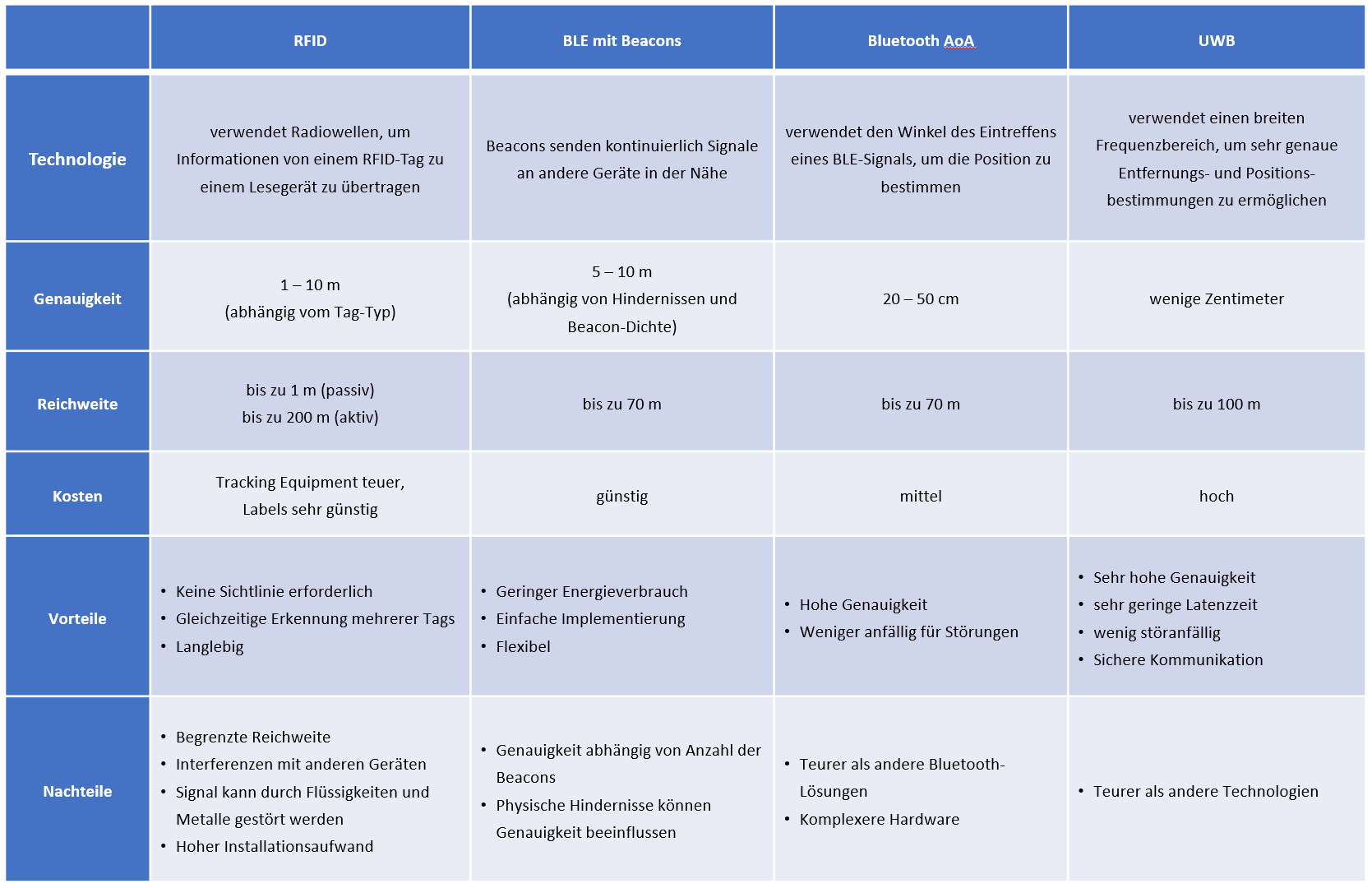
RFID Tracking
Die Technologie, bekannt als „Radio Frequency Identification“ oder RFID ist in Bereichen wie Warenlagern, Bibliotheken und im Einzelhandel bereit sehr weit verbreitet. Der Name selbst leitet sich von der Art und Weise ab, wie diese Technologie funktioniert: Durch die Identifizierung mittels Radiowellen. RFID nutzt elektromagnetische Felder, um automatisch Informationen von sogenannten „Tags“ zu erfassen, die an Objekten angebracht sind. RFID-Tags können passiv oder aktiv sein. Passive Tags benötigen keine eigene Stromversorgung, denn sie beziehen ihre Energie aus dem elektromagnetischen Feld, das vom Lesegerät emittiert wird, haben aber eine geringe Reichweite von wenigen Metern. Aktive Tags haben eine eigene Batterie und senden kontinuierlich Signale aus, haben aber eine höhere Reichweite von bis zu 200 Metern. RFID-Tracking kann eine statische Position bestimmen, indem das Lesegerät erkennt, ob ein Tag in seiner Reichweite ist oder nicht. Die Genauigkeit hängt von der Anzahl und Position der Lesegeräte ab. Ein großer Vorteil von RFID ist, dass keine direkte Sichtlinie zwischen dem Tag und dem Lesegerät erforderlich ist. Darüber hinaus können mehrere Tags gleichzeitig gelesen werden. Allerdings kann es zu Interferenzen mit anderen Funkwellen kommen, die die Signalqualität beeinträchtigen können und Materialien wie Flüssigkeiten und Metalle können das Signal stören, so dass bspw. Leuchtstoffröhren und große Maschinen die Lesereichweite verringern. Außerdem kann RFID-Tracking keine dynamische Position bestimmen, bzw. die Bewegung eines Objekts verfolgen, ist also nicht für eine kontinuierliche Wegeverfolgung oder ein nahtloses Tracking über größere Flächen hinweg geeignet. Das Tracking Equipment ist bei RFID relativ teuer und damit i.d.R. nur für sehr lokale Anwendungsfälle geeignet. Die Tags dagegen sind extrem günstig und klein, so dass problemlos sehr große Mengen von Teilen gelabelt werden können. RFID Tracking wird daher insbesondere im Waren- und Bestandsmanagement, bei Förder- und Transportsystemen, in Ausweisen, zur Warensicherung und zur Zeiterfassung eingesetzt.
BLE-Tracking mit Beacons
Beim „Bluetooth Low Energy“-Tracking, kurz BLE, spielen die sogenannten „Beacons“ eine zentrale Rolle. Der Name „Beacon“ bedeutet auf Deutsch „Leuchtfeuer“ oder „Signalgeber“, was genau das beschreibt, was diese kleinen Geräte tun: Sie senden kontinuierlich Signale aus. Diese Signale können von Geräten in der Nähe erkannt werden und durch die Messung der Signalstärke kann die Entfernung zum Beacon abgeschätzt werden. Ein Vorteil der Bluetooth-Funksignale ist, dass sie beim Senden der Signale die meisten Materialien durchdringen können. Beacons sind in verschiedenen Größen, Farben und Formen erhältlich, sodass sie sich für zahlreiche Einsatzzwecke eignen und in jede Umgebung unauffällig und einfach integriert werden können. Bekannt ist diese Ortungstechnologie insbesondere durch die iBeacons von Apple und die Eddystones von Google.
Die BLE-Tags sind günstig und die Batterien halten bis zu zehn Jahre lang, da die Technologie extrem wenig Energie verbraucht. Als Ortungstechnologie für die Indoor Positionierung in IoT-Projekten gibt es zwei verschiedene Ansätze. Zum einen können Beacons stationär verbaut werden und ein mobiles Gerät kann dann seinen eigenen Standort anhand der Beacons ermitteln. Alternativ wird das Beacon an dem zu verfolgenden Objekt angebracht und die Lesegeräte befinden sich an verschiedenen Kontrollpunkten.
UWB
Ultra-Breitband (Ultra-Wideband, UWB) ist eine Kurzstrecken-Funktechnik, die sich insbesondere durch eine extrem präzise Positionierungsfähigkeit auszeichnet. Diese Ortungstechnologie ist besonders von Apple AirTags bekannt. Der Name „Ultra-Wideband“ bezieht sich auf die breite Bandbreite der Funkwellen, die sie verwendet. Ultrabreitband-Funk kann mit sehr geringer Leistung (weniger als 0,5 Milliwatt) riesige Datenmengen über eine Entfernung von bis zu 100 Meter übertragen. Es hat auch die Fähigkeit, Signale durch Türen und andere Hindernisse hindurch zu übertragen, die dazu neigen, Signale mit begrenzteren Bandbreiten und höherer Leistung zu reflektieren. Die Positionsbestimmung stützt sich nicht auf die Signalstärkenmessung, wie es bei BLE der Fall ist, sondern nutzt ein Verfahren zur Messung der Laufzeit. Durch das Senden von kurzen und sehr breiten Funkimpulsen über diese breite Bandbreite und die Messung der Zeit, die diese Impulse benötigen, um von einem Sender zu einem Empfänger zu gelangen, kann die Position mit einer Genauigkeit von bis zu wenigen Zentimetern bestimmt werden. Es bietet die höchste Präzision auf großen Flächen mit vergleichsweise geringem Installationsaufwand. UWB ist von den Kosten mit RFID vergleichbar. Da die UWB-Tags genauso wie die BLE-Beacons mit höheren Kosten als RFID-Chips verbunden sind, ist UWB für sehr große Mengen eher nicht geeignet. Obwohl UWB in Bezug auf die Hardware teurer ist als viele andere Technologien, bietet es jedoch insbesondere bei Anwendungen, die eine hohe Genauigkeit erfordern, den unübertroffenen Vorteil der höchsten Präzision.
Bluetooth AoA
Eine weitere Ortungstechnologie zur Indoor-Positionierung ist Bluetooth AoA. Hierbei handelt es sich im Grunde auch um BLE-Technologie, aber unter Einbeziehung der Richtung der Strahlen („Angle of Arrival“). Wie der Name schon andeutet, bestimmt diese Methode den Winkel, unter dem ein Bluetooth-Signal bei einem Empfänger eintrifft. Damit ermöglicht Bluetooth AoA eine deutlich präzisere Positionierung als herkömmliches Bluetooth-Tracking. Mit Bluetooth AoA werden Genauigkeiten von unter einem Meter selbst über große Reichweiten hinweg erzielt, so dass man selbst in den herausforderndsten (Industrie-)Umgebungen zuverlässige Ortungsdaten in Echtzeit erhält.
Während die Hardware und Software für Bluetooth AoA zwar komplexer und teurer sind, bietet es dafür aber eine beeindruckende Genauigkeit und ist weniger anfällig für Störungen durch physische Barrieren. Bluetooth AoA stellt bei der Indoor Positionierung somit einen Kompromiss zwischen der UWB Technik und der klassische BLE-Beacon Technik dar. Daher wird Bluetooth AoA in IoT-Projekten nicht nur gerne als Ortungstechnologie für ein präzises Indoor-Tracking, wie z.B. in der Fertigung oder Logistik, der Lagerhaltung, dem Supply Chain Management eingesetzt, sondern auch bspw. auch bei der Indoor-Navigation und der Robotersteuerung.
Fazit
Jede der hier vorgestellten Ortungstechnologien für die Indoor Positionierung hat ihre eigenen Vorteile und Nachteile. Daher hängt die Auswahl des passenden Lokalisierungssystems immer von den jeweiligen spezifischen Zielen und Anforderungen, den Rahmenbedingungen und auch dem Budget des IoT-Projekts ab. In manchen IoT Anwendungsfällen kann auch eine Kombination von mehreren Ortungstechnologien für die Positionsbestimmung und das Tracking von Objekten in Innenräumen sinnvoll sein. RFID kann für größere Systeme mit vielen Tags wirtschaftlicher sein, während UWB für Anwendungen mit hoher Genauigkeit geeignet ist, aber tendenziell teurer ist. BLE bietet einen Mittelweg in Bezug auf Kosten und Genauigkeit, besonders wenn die vorhandene Infrastruktur (z. B. Smartphones) genutzt werden kann.
Wenn Sie auf der Suche nach der am besten geeigneten Technologie für die Indoor-Positionierung für Ihr IoT-Projekt sind, sprechen Sie uns an.
Unsere IoT-Spezialisten helfen Ihnen gerne bei der Auswahl und Implementierung der passenden Ortungstechnologie.